想对楼上的同学说,看了我们的源码后你会觉得毕设压力小更多
PaddlePaddle/models
DeepLab v3 是DeepLab语义分割系列网络的最新作,其前作有 DeepLab v1,v2, v3, 在最新作中,Liang-Chieh Chen等人通过encoder-decoder进行多尺度信息的融合,同时保留了原来的空洞卷积和ASSP层, 其骨干网络使用了Xception模型,提高了语义分割的健壮性和运行速率。其在Pascal VOC上达到了 89.0% 的mIoU,在Cityscape上也取得了 82.1%的好成绩,下图展示了DeepLab v3 的基本结构4:
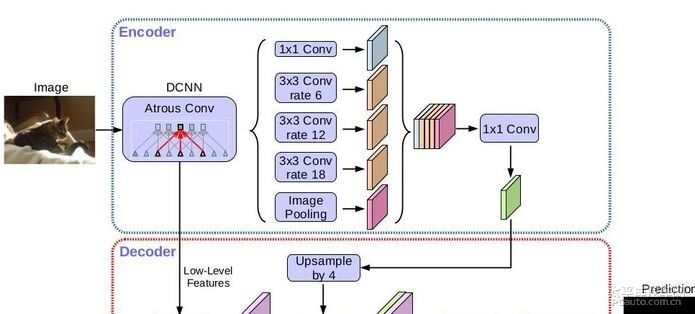
DeepLab v3 在主干网络之后连接了Encoder和Decoder,能够在扩大网络感受的同时获得更加高清的分割结果。
在PaddlePaddle的模型库中已经包含了DeepLab v3 的训练以及测试的代码。我们首先安装最新版本的PaddlePaddle并且下载PaddlePaddle的模型库:
pip install -U paddlepaddle
git clone https://github.com/PaddlePaddle/models.git
当模型仓库成功克隆,你将可以在目录fluid/PaddleCV/deeplabv3 下看到用于训练以及测试的代码:
ls fluid/PaddleCV/deeplabv3
├── models.py # 网络结构定义脚本
├── train.py # 训练任务脚本
├── eval.py # 评估脚本
└── reader.py # 定义通用的函数以及数据预处理脚本
二、开始训练
当数据和代码都已经准备好,我们可以开始训练了,训练的参数和指令如下:
CUDA_VISIBLE_DEVICES=0 FLAGS_fraction_of_gpu_memory_to_use=0.99
inplace_normalize=1 fuse_relu_before_depthwise_conv=1 python3
/home/cjld/nfs/liangdun/deeplabv3 /train.py --batch_size=-1 --train_crop_size=-1 --
total_step=10 --base_lr=0.005 --train_set=train --norm_type=gn --
save_weights_path=$YOUR_SAVE_WEIGHTS_PATH –dataset_path=$YOUR_DATASET_PATH
在这个命令中,我们没有使用任何预训练模型,从噪音开始训练DeepLab v3 。并且是直接使用全分辨率进行训练(1024x2048,batch size=1)。几个比较关键的参数解释如下:
环境变量CUDA_VISIBLE_DEVICES=0限制了训练过程仅使用一张GPU,如果存在多张GPU,可以通过修改参数来得到训练速度的提升。环境变量FLAGS_fraction_of_gpu_memory_to_use=0.99, 该环境变量将会让PaddlePaddle占用99%的显存,可以根据实际情况进行调节。环境变量inplace_normalize=1,该参数是PaddlePaddle进行显存优化的关键,打开该开关将会让框架对normalize layer进行 inplace 操作来优化显存,现在支持的 normalize layer 有 group normalize。环境变量fuse_relu_before_depthwise_conv=1,该参数是显存优化的另一个关键参数。这个参数会融合relu和depthwise conv来优化显存。参数--save_weights_path=$YOUR_SAVE_WEIGHTS_PATH, 这里你需要填入保存模型的路径。参数--dataset_path=$YOUR_DATASET_PATH, 这里你需要填入数据集的路径。
三、空间时间消耗分析
根据打印出来的信息,我们可以发现,PaddlePaddle在训练DeepLab v3 时,输入一张全分辨率的图片,显存消耗为10.2GB。得益于显存消耗小于11G,我们可以使用1080ti完成训练,训练中每次迭代速度约为0.85s。
我们还可以使用工具,分析DeepLab v3 各部分显存消耗情况:
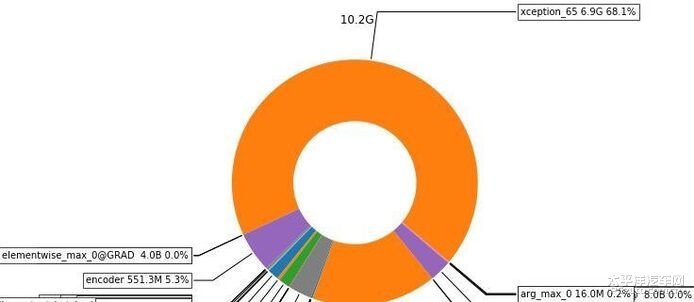
在该图中,显存消耗最多的是主干网络,占用了68.1%,其次是decoder部分,占用了16.4%,以及encoder占用了5.3%,剩下其他部分为损失函数和数据预处理的显存消耗。
显存消耗最多的是主干网络,占用了68.1%,我们可以继续查看主干网络内部显存消耗情况:
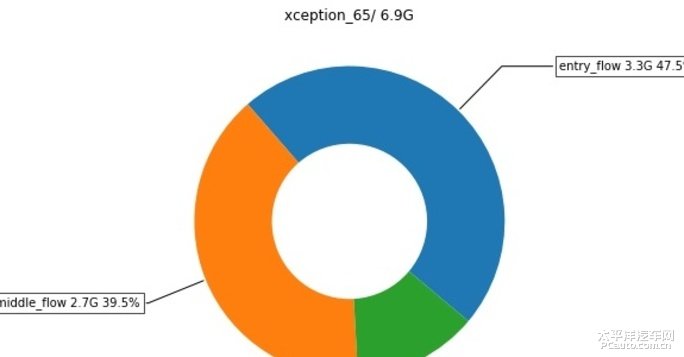
这个图展示了在主干网络中的显存消耗,Xception主干网络主要由三部分组成, EntryFlow,MiddleFlow,以及ExitFlow,可以发现显存消耗最大的是EntryFlow。
在上图中,我们可以发现,尽管Xception主干网络层数最多的部分是MiddleFlow,但是显存消耗最大的却是EntryFlow,这是因为在EntryFlow里的特征还没有被充分下采用,分辨率相当高,同时EntryFlow里的通道数也不容小觑,因此造成了EntryFlow巨大的显存开销,这也为我们的优化指明了方向。
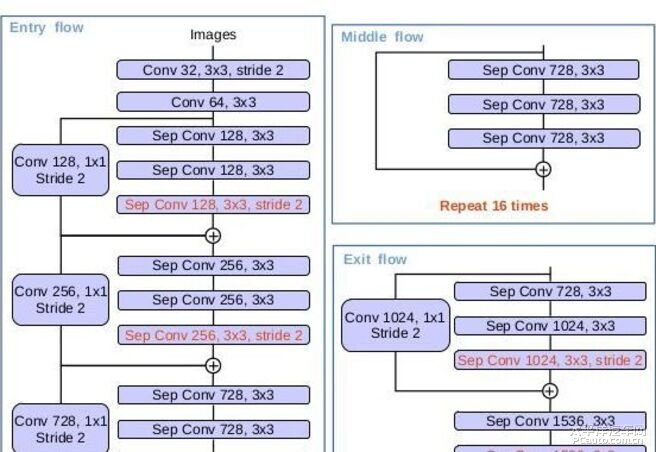
DeepLab v3 使用的主干网络 Xception, MiddleFlow中的分离卷积块重复了16次,层数相比较EntryFlow和ExitFlow要多得多,然而显存消耗最大的却是EntryFlow。
框架对比
除开对网络内部的显存消耗进行分析,我们还对不同框架的显存消耗进行了对比,下表展示了PaddlePaddle和TensorFlow1.12的显存消耗以及性能对比,以下对比实验使用的输入数据是1024x2048全分辨率的图片,batch size为1,测试设备P40(24G):

四、优化原理
这里我们采用的显存优化策略是 fuse_relu_before_depthwise_conv 和 inplace_normalize。顾名思义,fuse_relu_before_depthwise_conv 是讲relu和depthwise_conv融合为同一个operator, 达到显存的节省。而 inplace_normalize 则是使用原地操作来节省显存。在卷积神经网络中,conv normalize activation是常见模式,在这种模式下,使用这两种优化策略,可以节省3倍的显存。这两种优化策略归纳起来就是操作融合和原地计算, 是显存优化中的常见策略, 对于不同的框架常常需要耗费人力进行开发, 而我们通过paddle的显存优化可以很轻松的实现这一点。 该优化图示如下:
在该图中,红框标注的data为会消耗显存的数据块,可以看到,通过inpalce和fuse两种操作,原来需要存储6个数据块,优化后仅仅需要2个数据块。
在上图中,我们可以发现,inplace和fuse两种操作,都分别帮助我们在每一个conv normalize activation块中节省了1个数据块,所以显存节省的更多了,我们的分割网络也可以消耗更少的显存资源。

 扫一扫 轻松下载
扫一扫 轻松下载









