
 扫一扫 轻松下载
扫一扫 轻松下载
|
查看: 回复:27 |
YOLO v3深入理解
|
|
|
|
|
|

 图1 Darknet-53[1]
图1 Darknet-53[1]






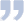






|
发表于
2019-08-18 18:13
13楼
|
|


|
发表于
2019-08-21 21:07
15楼
|
|




温馨提示:回复超10字可获1金币,有独特见解超30字可获3金币,灌水用户将扣除金币并锁号处理。希望广大车友共同维护论坛的友好回复氛围。
您可能感兴趣